 Digital Commons Help Center
Digital Commons Help CenterHow Can We Help?
Content Reporting ToolContent Reporting Tool
Overview
The Content Reporting Tool is a dedicated space in Digital Commons where Institutional Repository (IR) administrators can easily go to obtain the content-based information they need to report on. It is designed to host functions, analyses, or visualizations related to content-based reporting as DC community needs develop. The first of those functions is the Content Inventory.
What Does It Provide?
The Content Inventory available in the Content Reporting Tool generates a comprehensive site inventory in an .xlsx spreadsheet of all records and all metadata published or submitted (pending), across the entire repository. This allows IR managers to easily review and report on the content in their repository without needing to traverse into and out of individual collections. Utilizing Excel’s flexibility and manipulation options (e.g., sorting, filtering, deleting), the Content Inventory allows you to accomplish any of the multiple use cases mentioned below in a self-serve way.
Use cases:
- Analyze the growth of submissions and published records over time
- Check metadata quality across multiple collections
- Check for duplicates
- Analyze file count and file storage size totals
- Perform ad-hoc analyses on specific cross-sections of the repository
- View submitter ingest activity
Additions and improvements in the Content Inventory:
- Loads and performs quickly and reliably (even for very large repositories)
- Includes additional key metadata (e.g., submission dates, posted dates, author affiliations and emails, seasons, disciplines, existence of files [native/PDF], file name, file size, publication, and community)
- Generates .xlsx spreadsheets (instead of .xls)
- Offers a streamlined user experience
Access the Content Reporting Tool
All IR managers who have the “View Digital Commons Dashboard” permission can access the Content Reporting Tool and the Content Inventory function within it.
A link to the Content Reporting Tool is listed under Site Administration Tools on the My Account page.
On the Content Reporting Tool page, an option will appear to generate a Content Inventory as described below.
Generate a Content Inventory
Once you navigate to the Content Reporting Tool page, click the Request content inventory button. A new entry will appear in the “Content inventory jobs” table with an “In Progress” status.
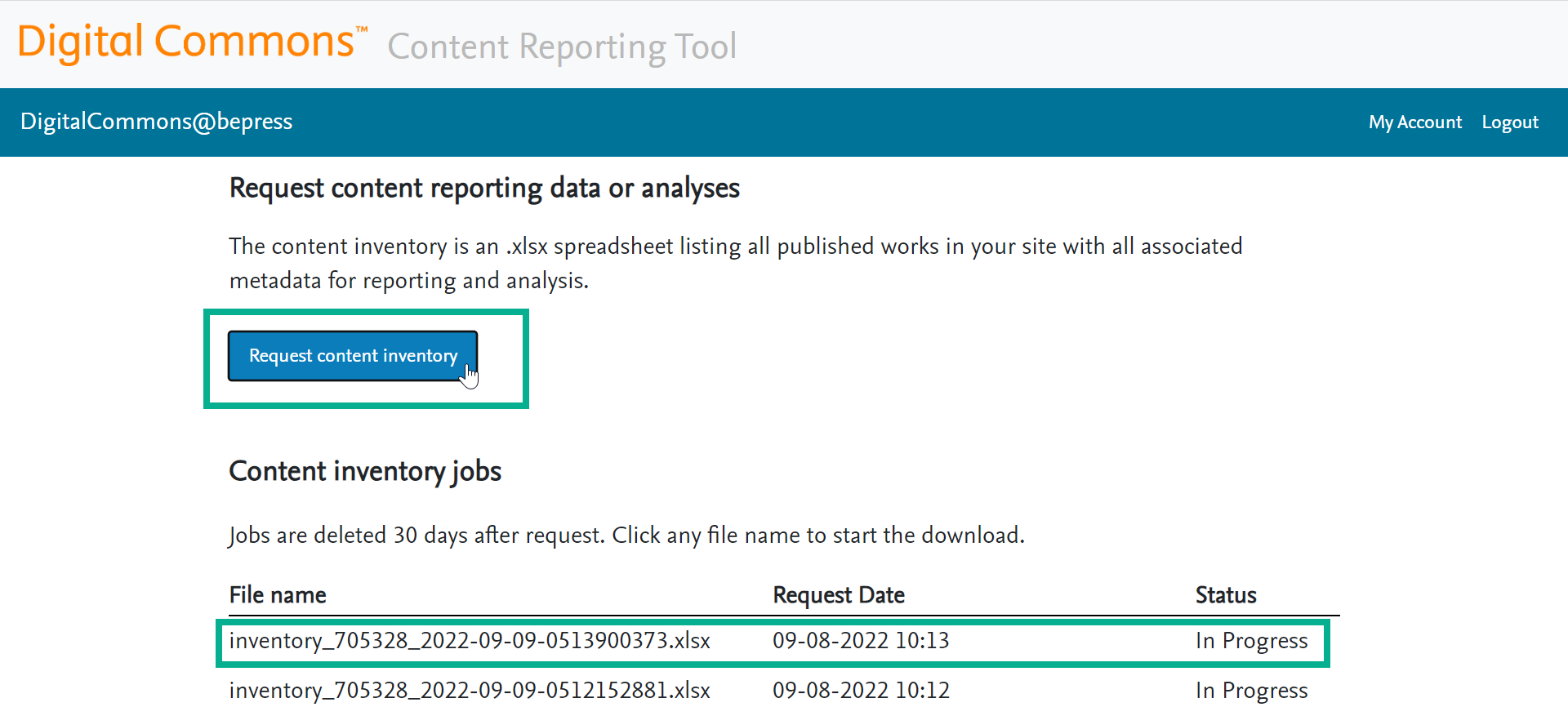
The status will change to “Success” once the Content Inventory job is complete. This should only take a few minutes for most DC sites, although very large repositories can take up to 30 minutes or a couple of hours (for the largest IRs).
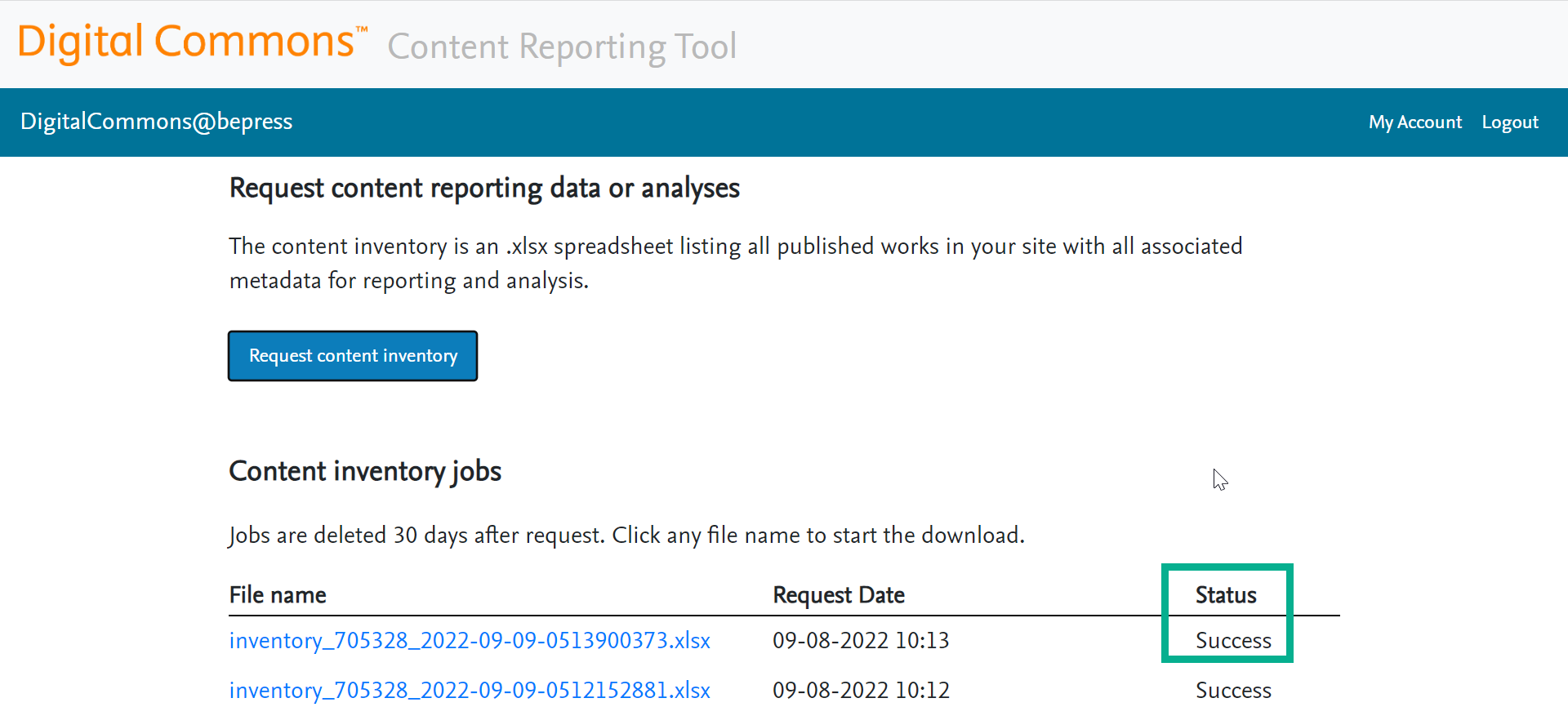
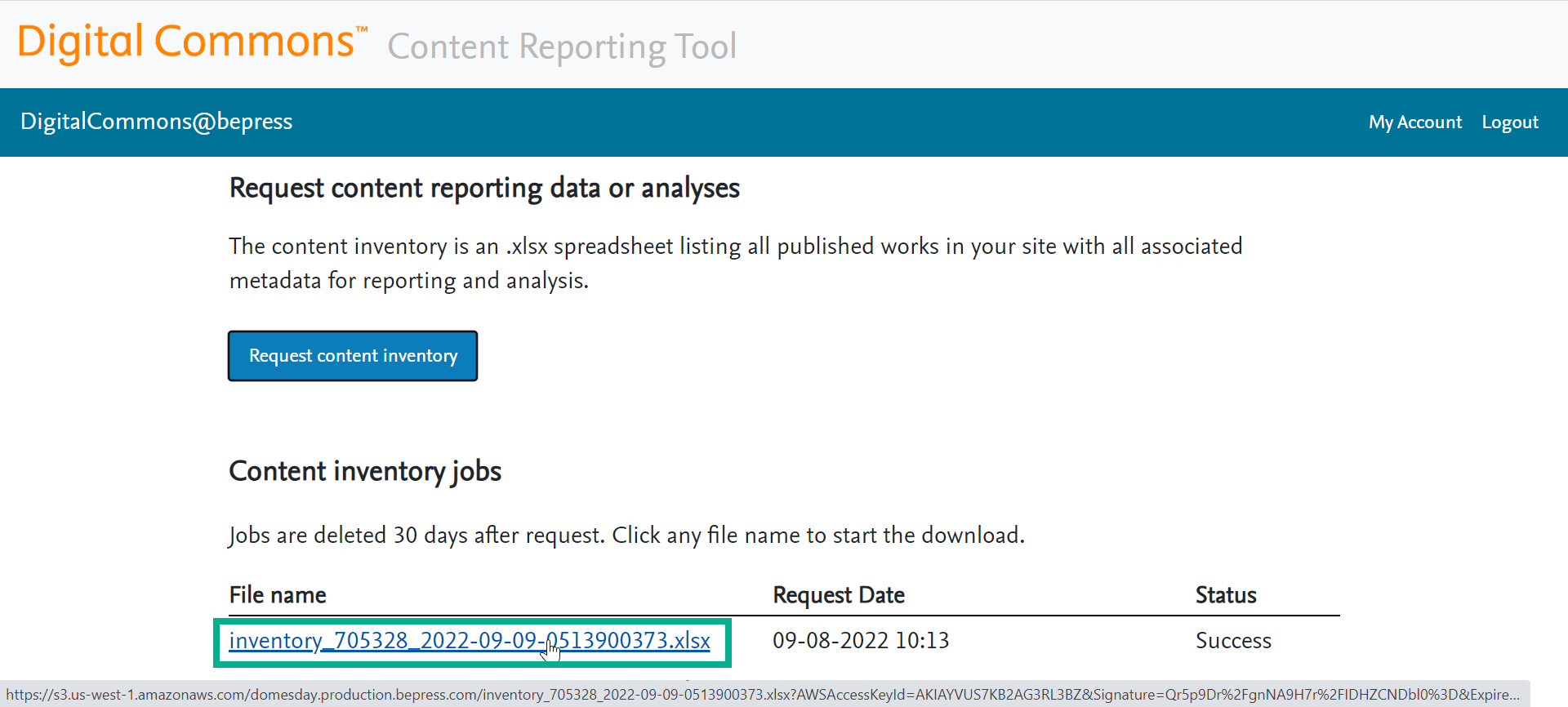
The file name will become a link to download the Content Inventory in .xlsx format once the job completes successfully.
You can view and access past jobs in the same table. Jobs are retained for 30 days before being deleted. Jobs listed are specific to each user, so users cannot see jobs requested by others.
Use the Content Inventory Spreadsheet
Basics
You may download a current or past Content Inventory (up to 30 days after requested) following the steps above. The report is in the form of an Excel .xlsx spreadsheet.
The spreadsheet includes all records and all metadata published or submitted (pending), across the entire repository. Withdrawn or rejected submissions are not included.
You may use Excel functions to review and manipulate the inventory as needed (e.g., adjust column widths, hide/delete/rearrange columns, freeze headers in view, filter and sort by specific columns, delete rows/columns, calculate counts and sums, generate graphs/tables, etc.). The fields are arranged into useful groupings as described below.
How the fields are arranged
Fields on the spreadsheet are generally organized into four sections, moving from left to right:
- Fields that are used most frequently in content reporting are in the initial section on the left (fields like title, submission date, submitted by)
- These fields include several author fields: a field that contains all authors together and then fields for each individual author separated into first, middle, last, suffix
- In the next section are other standard fields like abstract that are typically enabled in most publications
- Custom and non-standard fields from all publications appear next
- On the right are back-end metadata that show the publication (series, journal, etc.), whether a submission has a full text, and the community if the publication is in a community
Interpreting individual fields
Many fields on the Content Inventory are self-explanatory, such as title and abstract. However, since the Content Inventory provides all metadata including system fields, some fields may need additional clarification if you haven’t worked with them before. Please ask your consultant if you would like further details about any specific fields appearing in the Content Inventory.
FAQs
How can I isolate items for a particular community or series/collection?
The Content Inventory includes publication/collection/community metadata that can be sorted and manipulated in the generated Excel spreadsheet to conduct series/collection-level analyses.
Can I pre-select the metadata I want?
It is not possible to select specific metadata prior to generating a Content Inventory. However, columns representing metadata fields in the Excel inventory can easily be moved or deleted to isolate metadata of interest.
How can I see where a work is collected in the repository?
The “publications_collected_into” column in the last section of the spreadsheet lists the publications, if any, where a work has been collected using the Collection Tool.
How long do I need to wait for my job to complete?
The time to prepare the inventory will vary depending on the size and nature of your repository, as well as traffic levels in the application. Inventory preparation should take between a few minutes to 30 minutes in most cases, but can also last as long as a couple of hours for the very largest repositories.